Disaster recovery reference architecture: Kyndryl Cloud Uplift region-to-region – warm recovery
The following diagram shows a high-level overview of a disaster recovery workflow in Kyndryl Cloud Uplift.
In this example, a second Kyndryl Cloud Uplift region is used as a warm disaster recovery location for an application running in Kyndryl Cloud Uplift. For an overview of the various disaster recovery scenarios, see Disaster recovery reference architectures.
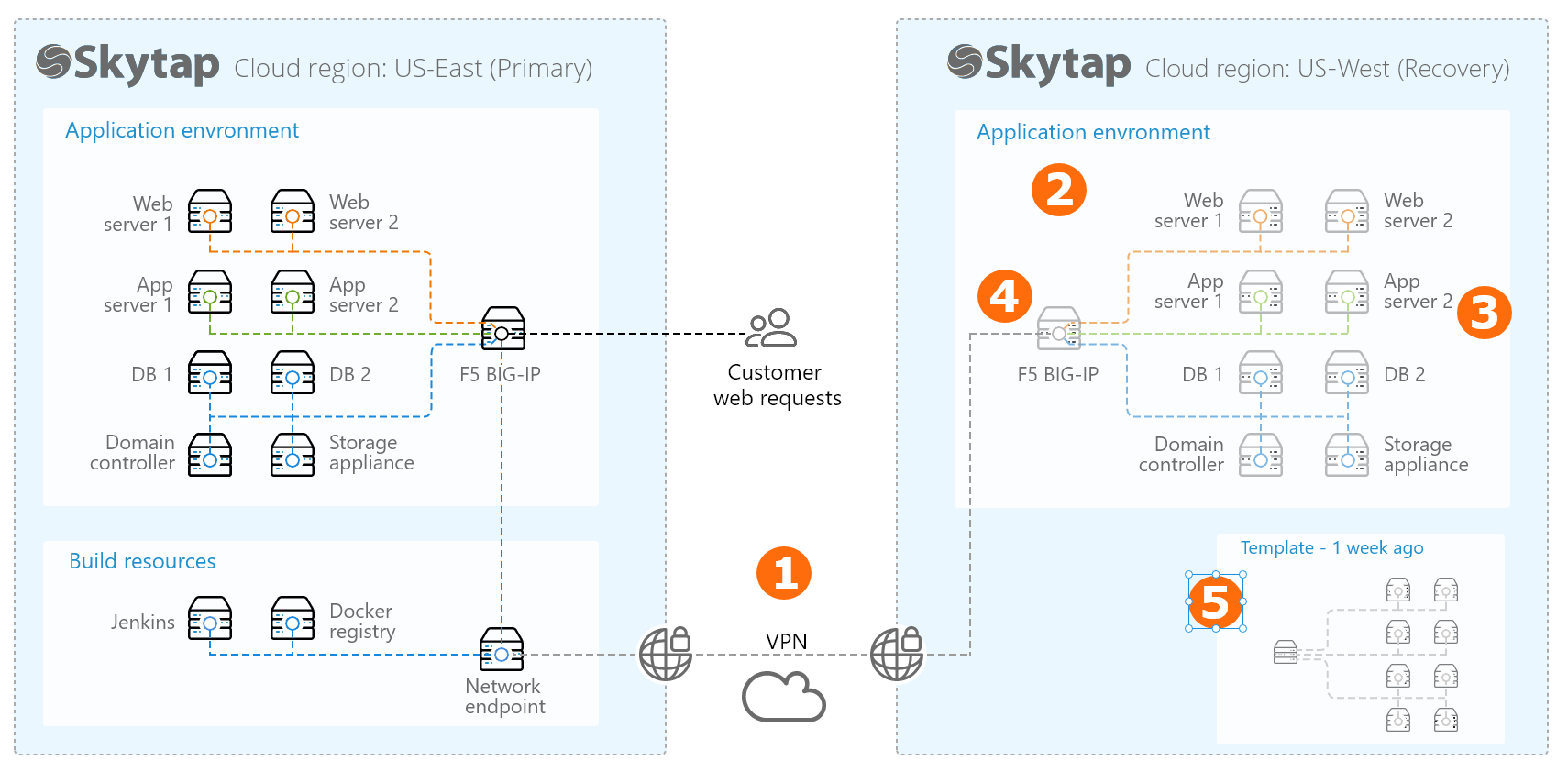
This disaster recovery workflow uses several Kyndryl Cloud Uplift features.
-
Create a VPN connection between your Kyndryl Cloud Uplift regions.
For example, run a firewall appliance in each Kyndryl Cloud Uplift region, and use a Kyndryl Cloud Uplift VPN to create a secure connection between the regions.
The VPN connection can be used to send updated application files to your recovery environment or to sync the databases in the two environments.
For more information, see Managing VPNs and Private Network Connections.
-
Create a copy of your application stack in a second Kyndryl Cloud Uplift region.
-
Use our copy-to-region feature to easily create a copy of your virtual environment in another Kyndryl Cloud Uplift region.
For more information, see Copying an environment to another region.
-
Share the second copy of the virtual environment with any Kyndryl Cloud Uplift users who will need access to it during disaster recovery.
-
Add the virtual environment to a project, and give access to any users who need to view, use, or edit the environment. Users can have different levels of access, depending on their project role.
Give the project an easily identifiable name, such as Disaster recovery resources.
For more information, see Sharing resources with projects.
-
If you use a Private Network Connection for secure access between your corporate network and your primary Kyndryl Cloud Uplift region, set up a Private Network Connection between your corporate network and your recovery region. For more information, see Managing VPNs and Private Network Connections.
-
-
-
Keep a subset of the critical VMs running. Suspend the other VMs in the recovery environment.
For example, keep the domain controller and database servers running and connected to the primary environment via the VPN connection. Synchronize the data in real-time or on a regular schedule (depending on your business requirements) to reduce your data recovery time. Follow the vendor’s recommendations for data replication and failover best practices.
To manage costs, suspend VMs that don’t need to be updated as frequently, like your application or web servers.
-
Attach a public IP address to the network appliance in the recovery environment.
For more information, see Attach a public IP address to a VM.
-
Periodically update the entire application stack and create a template backup.
On a schedule based on your business requirements:
- Start the remaining VMs in the recovery environment.
- Use your standard configuration management tooling (Ansible, Puppet, etc.) to update the VMs that had been suspended with the latest operating system and application updates.
- Perform a “smoke test” of the recovery environment. Use your standard test process to validate that the application works as expected and that it functions properly as a disaster recovery environment.
-
Save the updated environment as a backup template.
Give the template a unique and discoverable name, such as ApplicationName_DR_2018_04_01.
- Add the template to the project you created earlier. Validate that the project members have the appropriate level of access to create environments from the template.
During disaster recovery cutover
Follow your organization’s documented disaster recovery procedures to:
- Start the remaining VMs in the recovery environment.
- Use your standard configuration management tooling (Ansible, Puppet, etc.) to update the VMs that had been suspended with the latest operating system and application updates.
- Update your DNS service to direct traffic to the public IP address in the recovery environment.
When failing over to an alternate region, you may see different application response times. Users who are further away from the recovery location may experience slower response times, due to network latency.
For other disaster recovery examples, see Disaster recovery reference architectures.